1.정규화되어 저장된 데이터를 액세스하는 방법, 관계형 데이터베이스 조인의 개요
 |
| - 관계형 데이터베이스에서는 정규화를 강조하기 때문에 관리하고자 하는 정보가 필연적으로 다양한 테이블에 나누어져 저장되고 테이블 간에는 관계를 갖고 있으며 이렇게 저장된 데이터를 다시 결합하여 액세스 하기 위한 방법으로 조인 기술 사용 |
- 아주 단순한 트랜잭션 처리가 아니라면 대부분의 데이터 처리는 하나 이상 테이블의 데이터를 필요
2. Nested Loops Join 및 Sort Merge Join
가. Nested Loops Join 설명
| 구분 | 설명 | |
| 개념 | - 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 조합하는 조인 방식 | |
| 동작원리 | 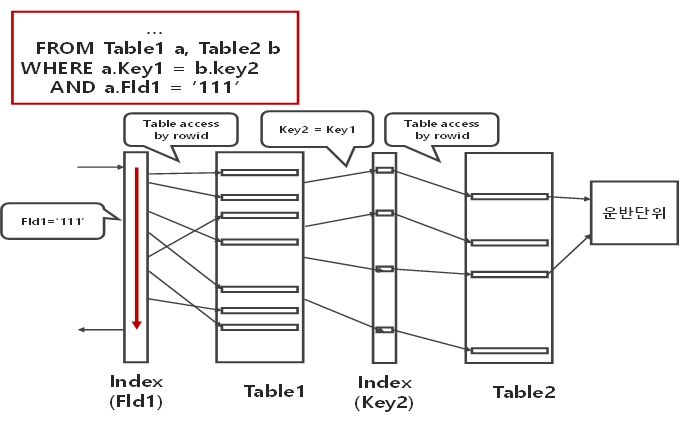 |
|
| - 먼저 Table1의 Fld1 인덱스를 경유하여 Fld1=’111’인 처리범위 중 첫 번째 로우 액세스 - Fld1 인덱스에 있는 Rowid에 의해 Table1의 로우 액세스 - 여기서 성공한 것에 대해 Table1의 Key1의 상수값을 이용하여 Table2의 key2 인덱스로 대응되는 인덱스 로우 검색 (대응되는 로우가 없으면 처음으로 돌아가 다음 건 시도) - 한 싸이클이 돌았으면 다시 Fld1 인덱스의 두 번째 로우를 읽어 위 작업 반복 - 부분범위처리가 가능하다면 운반단위가 채워질 때까지 수행하고 전체범위처리라면 Fld1범위가 끝날 때까지 계속(Nested)해서 반복(Loops) 수행 |
||
| 주요특징 | 순차적 | - 선행테이블의 처리범위에 있는 각각의 로우들이 순차적으로 수행되고 테이블간 순차적으로 연결 |
| 선행적 | - 먼저 액세스되는 테이블의 처리 범위에 의해 처리량 결정 | |
| 종속적 | - 나중에 처리되는 테이블은 앞서 처리된 값을 받아 액세스 | |
| 랜덤액세스 | - 주로 랜덤 액세스 방식으로 처리 - 선행 테이블의 인덱스를 액세스하는 방법은 첫 번째 로우만 랜덤 액세스이고 나머지는 스캔이지만 연결작업은 모두 랜덤 액세스로 수행 |
|
| 선택적 | - 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두 사용되지 않으며 연결되는 방향에 따라 사용되는 인덱스들이 전혀 달라질 가능성 존재 | |
| 방향성 | - 연결고리의 인덱스 유무에 따라 액세스 방향 및 수행속도에 많은 차이 발생 | |
| 부분범위처리 | - 선행하는 집합의 하나씩의 로우를 대상으로 연결을 진행하기 때문에 부분범위 처리조건을 만족하고 있다면 운반단위가 채워지는 순간에 우선 멈추는 것이 가능 | |
| 체크조건의 영향력 | - 연결작업을 수행한 후 마지막으로 체크되는 조건은 경우에 따라 수행속도에 미치는 영향 발생 | |
- Nested Loops 조인처럼 각각의 연결할 대상에 대해 일일이 랜덤 액세스를 하지 않기 위한 방법 필요
나. Sort Merge Join 설명
| 구분 | 설명 | |
| 개념 | - 조회의 범위가 많을 때 주로 사용하는 조인 방법론이며 양쪽 테이블을 각각 Access 하여 그 결과를 정렬하고 그 정렬한 결과를 차례로 Scan 해 나가면서 연결고리의 조건으로 Merge를 하는 방식 | |
| 동작원리 |  |
|
| - Table1은 Fld1 인덱스를 경유하여 Fld1=’111’이 범위를 차례로 액세스 한 후 성공한 것들에 대해서만 연결고리인 Key1의 값으로 정렬 - Table2도 Col1 인덱스를 경유하여 Col1=’10’인 범위를 차례로 액세스하고 연결고리인 Key2의 값으로 정렬 - 두 개의 정렬된 결과를 스캔하면서 Key1 = Key2를 만족하는 로우를 찾도록 머지하여 운반단위가 채워지면 추출 - 이 방식은 정렬해 둔 결과를 스캔하면서 연결하므로 연결작업에는 랜덤 액세스가 미발생 |
||
| 주요특징 | 동시적 | - 양쪽 집합이 모두 준비가 완료되어야 만 머지를 시작할 수 있어 순차적 처리가 불가능 |
| 독립적 | - 각 집합이 준비작업을 할 때 다른 집합에서 처리한 결과를 제공받지 않는다. | |
| 전체범위처리 | - 정렬 준비가 완료된 후에 조인을 시작할 수 있어 부분범위처리 불가능 | |
| 스캔방식 | - 각자의 처리범위를 줄이기 위해서 인덱스를 사용하는 경우만 랜덤 액세스가 발생할 수 있으나 연결하는 머지 작업은 스캔 방식 이용 | |
| 선택적 | - 주어진 조건에 있는 모든 컬럼들이 인덱스를 가지고 있더라도 모두 사용되지 않으며 연결고리가 되는 컬럼은 인덱스를 전혀 사용하지 않는다. | |
| 무방향성 | - 조인의 방향과는 거의 무관 | |
- Sort Merge 조인에서 가장 중요한 것은 정렬작업의 최적화에 있으며 정렬 작업이 메모리 내 정렬영역(Sort_area_size)의 크기가 적으면 정렬작업에 대한 부하로 Nested Loops 조인보다 느려질 가능성 존재
- 데이터 처리 범위가 날이 갈수록 초대형으로 증가하면서 Sort Merge 조인으로 해결에 어려움 발생
3. Hash Join 및 Semi Join
가. Hash Join 설명
| 구분 | 설명 | |
| 개념 | - 선행 테이블에 Hash Function을 적용하고 Hash Area에 해시테이블(Hash Table)을 구성하고 후행테이블을 차례로 Hash Function을 이용해 해시테이블과 조인하는 기법 | |
| 동작방식 | 인 메모리 해쉬조인 | - 전체 빌드입력이 해쉬영역(Hash_area_size)에 모두 위치할 수 있는 경우 수행하는 방식 |
| 유예 해쉬조인 | - 빌드입력이 해시영역에 모두 위치시킬 수 없는 경우 먼저 전체를 빌드입력과 검색입력을 수행하여 여러 개의 파티션에 분할하고 해쉬영역을 초과할 때마다 임시 세크먼트에 파티션을 저장하여 수행하는 방식 | |
| 동작원리 (인-메모리 해쉬조인기준) |
 |
|
| (1) 통계정보를 참조하여 보다 효과적인 카디널리티를 갖는 집합을 빌드입력으로 선택 (2) 팬아웃, 즉 파티션 수를 결정 (3) 빌드입력이 조인키에 대하여 1차 해쉬함수를 적용하여 저장할 파티션 결정 (4) 2차 해쉬함수를 적용하여 해쉬값 (Hash Value)를 생성 (5) 해쉬값을 이용하여 해쉬 테이블을 만들고 해당 파티션의 슬롯에 저장 (6) 검색입력의 필터링을 위해 사용할 비트맵 벡터 생성 (7) 빌드입력의 처리범위를 모두 처리할 때까지 반복수행 (8) 검색입력의 처리범위를 액세스하기 시작하여 조건을 만족하지 않으면 버리고 그렇지 않으면 다음을 실행 (9) 첫번째 해쉬함수를 적용하여 비트맵 벡터를 필터링, 여기서 찾을 수 없으면 해당 처리는 종료되고 다음 검색입력 대상으로 이동 (10) 필터링을 통과한 것은 2차 해쉬함수를 적용하여 해쉬 테이블을 읽고 해당 파티션을 찾아 슬롯에서 대응로우 검색 (11) 조인이 되면 SELECT-List에 기술된 로우를 완성하여 운반단위에 저장 (12) 이러한 작업을 반복해서 수행하여 계속 운반단위에 저장 (13) 정해진 운반단위가 채워지면 리턴 (14) 이러한 방식으로 검색입력이 처리범위가 끝날 때까지 반복 수행 |
||
- 유예 해쉬조인은 빌드입력의 처리범위를 처리하다가 해쉬영역을 초과하면 파티션 테이블에 위치정보를 남기고 디스크로 이동
나. Semi Join 설명
| 구분 | 설명 | |
| 개념 | - 조인과 매우 유사한 데이터 연결 방법을 의미하며 서브쿼리를 사용했을 때 메인쿼리와의 연결하는 처리 기법 | |
| 조인과 서브쿼리의 차이 |  |
|
| - TABLE1, TABLE2를 같은 조인 조건으로 연결할 때 조인과 세미조인으로 표현 - 두 테이블의 관계 형태에 따라 그 결과 집합이 나타나는 형태를 우측 도표로 표현 - 조인의 경우 집합의 곱 à 1 * 1 = 1, 1 * m = m, m * 1 = m, m * m = mm - 조인은1:1 조인은 동일한 집합이 되고 1:m이나 m:1은 모드 m 집합이 된다. 그러나 m:m 조인을 하면 카티젼 곱의 집합이 나타나게 된다. - 세미조인의 경우 결과의 집합은 언제나 메인쿼리의 집합과 동일 - 도표에서 세미조인의 결과를 확인해보면 TABLE1과 동일 - 세미조인은 조인 과정에서 등장한 컬럼들을 사용할 수 있는 상속성이 존재하며 메인쿼리에는 서브쿼리의 집합에 있는 컬럼들의 사용이 불가능 |
||
| 주요유형 | Nested Loops형 세미조인 | - 어떤 집합이 먼저 수행되어 거기서 얻은 상ㅅ후값을 연결고리를 통해 대응시키는 방법 - 서브쿼리가 먼저 수행되어 SELECT-List의 연결고리 값을 상수값으로 만들고 이것을 메인쿼리 연결고리에 대응시키는 방법과 메인쿼리가 먼저 수행되어 상수값이 된 연결고리 값을 서브쿼리의 연결고리에 제공하는 방법이 모두 발생 가능 |
| Sort Merge형 세미조인 | - 연결고리의 이상이 발생하거나 대량의 데이터를 연결해야 할 때는 세미 조인에서도 SortMerge형 조인을 적용 - SortMerge 형태로 수행해야하는 이유와 효과는 조인과 거의 동일 |
|
| 해쉬형 세미조인 | - 필터 형식으로 처리되는 세미 조인은 랜덤 위주의 액세스가 발생하므로 만약 대량의 연결을 시도했을 때 커다란 부담이 될 가능성이 존재 - 위 문제를 해결하기 위해 Sort Merge 형으로 유도할 수 있지만 일반적으로 해쉬 조인이 수행속도가 유리하여 이를 활용 - 서브쿼리에 ‘HASH_SJ’ 힌트를 사용하여 세미 조인이 해쉬형으로 수행되도록 유도 |
|
| 부정형 세미조인 | - 조인의 연결고리 조건에 부정형(Not)이 들어 있다면 양쪽 집합을 연결하는 것 자체가 이미 논리적으로 어려움 - 조인의 비교연산자는 긍정형을 사용하고 이것을 괄호로 묶은 것을 ‘NOT IN’, ‘NOT EXISTS’를 이용하여 집합간의 연결은 기존의 세미조인으로 실시하고 그 결과의 판정만 반대로 하는 방식을 적용 |
|
- 조인 성능을 확보하기 위해 가장 유리한 형태의 조인유형을 선택하고, 연결고리의 상태를 확인, 연결고리 외 컬럼들의 조건에 사용된 연산자와 인덱스의 상태를 비교하여 처리범위를 가장 줄여주는 것이 필요
※ 출처 : 대용량 데이터베이스 솔루션 Vol 1 관계형 데이터베이스 활용 원리편 (EN.CORE, 이화식 지음)
'IT기술노트 > 데이터베이스' 카테고리의 다른 글
| 공공데이터 예방적 품질관리 방안 (1) | 2024.06.03 |
|---|---|
| 데이터베이스 보안 3대요소 (0) | 2023.10.06 |
| 벡터 데이터베이스 (Vector Database) (0) | 2023.07.06 |
| DQC (Database Quality Certification) (0) | 2022.12.08 |
| 데이터 무결성 (Data Integrity) (0) | 2022.09.01 |
| 다중버전 동시성 제어(MVCC, Multi-Version Concurrency Control) (1) | 2021.09.20 |
| 데이터베이스 샤드(Database Shard) (0) | 2021.03.07 |
| In-Memory Database (0) | 2021.03.07 |




댓글