I. 분산 데이터베이스의 개요
가. 분산 데이터베이스의 정의
- 논리적으로 하나의 시스템으로 구현되어 있으나, 물리적으로는 네트워크를 통하여 분산화된 형태로 관리되는 데이터베이스
나. 분산 데이터베이스의 목적
- 데이터처리 지역화, 운영 및 관리의 지역화, 처리/부하분산 및 병렬처리, 데이터 가용성 신뢰성 향상
다. 분산 데이터베이스의 특징 (투명성)
|
특징 |
설명 |
|
위치 투명성 |
- 사용자는 접근할 데이터의 물리적 위치를 알 필요가 없는 성질 |
|
복제 투명성 |
- 사용자는 접근할 데이터가 물리적으로 여러 곳에 복제되어 있는지 알 필요 없는 성질 |
|
병행 투명성 |
- 여러 사용자가 동시에 분산 데이터베이스에 대한 트랜잭션을 수행하는 경우에도 결과에 이상이 발생하지 않는 성질 |
|
분할 투명성 |
- 사용자가 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 사이트에 저장되어 있음을 알 필요가 없는 성질 |
|
장애 투명성 |
- 데이터베이스가 분산되어 있는 각 지역의 시스템이나 통신망에 이상이 생기더라도 데이터의 무결성을 보존 할 수 있는 성질(2PL) |
라. 분산 데이터베이스 설계방식
- Top-down 방식, Bottom-up 방식, Hybrid 방식
II. 분산 데이터베이스의 구조 및 구성요소
가. 분산 데이터베이스의 구조
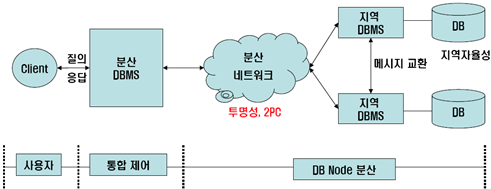 |
나. 분산 데이터베이스의 구성요소
|
구성요소 |
설명 |
|
분산 DBMS |
- 여러 지역에 나누어진 Local DBMS를 하나의 커다란 광역 DBMS로 관리 할 수 있도록 지원 |
|
Local DBMS |
- 질의 처리기, 동시성 처리, 보안 처리기, 복구 관리기, 저장장치 관리기 등 5개의 모듈로 구성, OLTP의 기본 성격인 ACID 지원 |
'IT기술노트 > 데이터베이스' 카테고리의 다른 글
| In-Memory Database (0) | 2021.03.07 |
|---|---|
| DB Smell (0) | 2021.03.07 |
| DB Refactoring (1) | 2021.03.07 |
| Streaming DBMS (0) | 2021.03.07 |
| XML DB (0) | 2021.03.07 |
| 공간DB (0) | 2021.03.07 |
| Tiny DB (0) | 2021.03.07 |
| 데이터 프로파일링(Data Profiling) (0) | 2021.03.07 |




댓글