|
강화학습, Model-Free, Q함수, 벨만 방정식, 마르코프 가정 |
I. Q-러닝의 개요
가. Q-러닝(Q-Learning)의 정의
- 특정한 상태에 놓여있을 때 취할 수 있는 각각의 행동에 대한 효용(Q)값을 미리 계산하여, 마르코프 의사결정 과정에서 최적의 정책을 찾는 강화학습 방법
II. Q-러닝의 프로세스 및 구성요소
가. Q-러닝의 프로세스
|
프로세스 |
설명 |
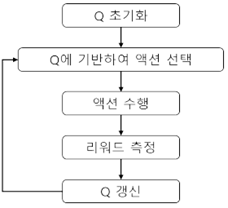 |
1) Value table Q(상태, 액션) 초기화 2) 현재 상태에 대한 관찰 수행 3) 액션 선택 정책에 기반하여 현재 상태에 맞는 액션 선택 4) 새로운 상태와 보상에 대한 관찰 5) 보상에 대한 관찰 및 다음 상태에서의 보상 최대치 업데이트 6) 새로운 상태 설정 및 반복 수행 |
- 보상에 의한 정책에 따라 액션을 수행하고, 보상의 측정 및 업데이트 수행
나. Q-러닝의 구성요소
|
구분 |
세부특징 |
설명 |
|
정책 (Policy) |
- 최고보상 - 미래보상 관찰 |
- 가장 높은 Q값을 가지도록 액션 선택 규칙 - |
|
벨만 방정식 (Bellman equation) |
- 정책반복 - 재귀함수 |
- 최적의 정책을 찾기 위한 반복 수행 - 현재 상태의 최고보상과 미래보상의 최대값 합계 |
|
Q-러닝 알고리즘 |
- 테이블 기반 - 반복적 근사 |
- 벨만 방정식의 반복수행으로 Q함수 근사 가능 - 각 행은 상태에 해당하며, 각 열은 액션에 대응 |
- 테이블 형태의 Q-러닝 알고리즘의 사이즈 문제에 대한 해결 방안으로 DQN 등장
III. Q-러닝 사이즈 문제 해결을 위한 DQN 사례
|
구분 |
동작구성도 |
설명 |
|
ConvNet 활용 |
 |
- 상태와 액션을 입력 받아 해당 상태와 액션의 Q 함수 값을 출력하는 신경망 정의 |
- 신경망에서 손실함수는 제곱오차로 정의가능하며 테이블 형태의 Q-러닝 함수의 오차장의와 유사
'IT기술노트 > 인공지능' 카테고리의 다른 글
| 활성화 함수 (0) | 2021.03.06 |
|---|---|
| 퍼셉트론(Perceptron) (0) | 2021.03.06 |
| MCTS(Monte Carlo Tree Search) (0) | 2021.03.06 |
| Feed Forward Model (0) | 2021.03.06 |
| 은닉 마르코프(HMM, Hidden Markov Model) (0) | 2021.03.06 |
| R-CNN (0) | 2021.03.05 |
| LSTM(Long Shot Term Memory) (0) | 2021.03.05 |
| RNN(Recurrent Neural Network) (0) | 2021.03.05 |




댓글