반응형
I. 데이터마이닝 알고리즘의 개요
가. 데이터마이닝 알고리즘의 정의
- 복잡한 문제들을 해결하기 위해 비즈니스 및 과학적 기관들에 의해 다양한 방법과 알고리즘
나. 데이터마이닝 과업 유형
- 예측, 연관, 분리
II. 데이터마이닝 과업과 알고리즘
|
분석기법 |
내용 |
|
연관성 분석 (Associate) |
- 여러 개의 트랜잭션들 중에서 동시에 발생하는 트랜잭션의 연관관계를 발견 - 지지도, 신뢰도, 향상도 (Apriori 알고리즘) |
|
연속성 규칙 (Sequence) |
- 개인별 이력데이터를 시계열적 분석하여 트랜잭션의 향후 발생 가능성을 예측 |
|
분류 규칙 (Classification) |
- 이미 알려진 특정그룹에 특징을 부여하여 정의된 분류에 맞게 구분 |
|
데이터 군집화 (Clustering) |
- 상호간에 유사한 특징을 갖는 데이터들 집단화하는 과정 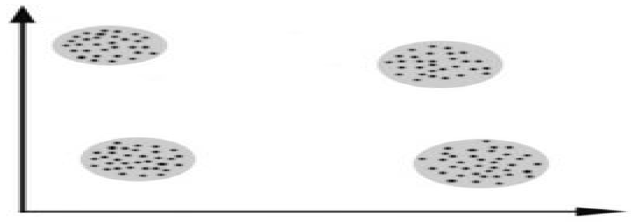 - K-means Clustering 알고리즘: K개의 묶음으로 군집하여 분류하는 기법 |
|
특성화 (Characterization) |
- 데이터 집합의 일반적인 특성을 분석 - 데이터의 요약 과정을 통하여 특성 규칙을 발견 |
|
의사결정트리 (Decision Tree) |
- 과거 축적된 데이터를 분석하여 나무모형으로 분류  |
|
신경망 분석 |
- 인간 두뇌세포 모방한 개념으로 학습을 통한 예측 |
반응형
'IT기술노트 > 빅데이터' 카테고리의 다른 글
| 통계 결측치(Missing Value) (0) | 2021.03.03 |
|---|---|
| 박스플롯 분석 (0) | 2021.03.03 |
| 결측치, 이상치 (0) | 2021.03.03 |
| 탐색적분석(Exploratory Data Analysis) (0) | 2021.03.03 |
| KNN(K-Nearest Neighbor) (0) | 2021.03.03 |
| 군집분석(Cluster Analysis) (0) | 2021.03.03 |
| K-Means (0) | 2021.03.03 |
| Apriori (0) | 2021.03.03 |


댓글