반응형
I. K-Means의 개요
가. K-Means(K 평균군집)의 정의
- 두 개체 간의 비 유사성을 정량화하여 위에서 아래(Top-down)방식으로 K개의 군집을 형성하는 방법
나. K-Means 알고리즘의 특징
- 반복적, 알고리즘 간단 및 대규모 적용 가능, 초기 부적절한 병합에 대한 회복
II. K-Means 알고리즘의 원리 및 절차
가. K-Means 알고리즘의 원리
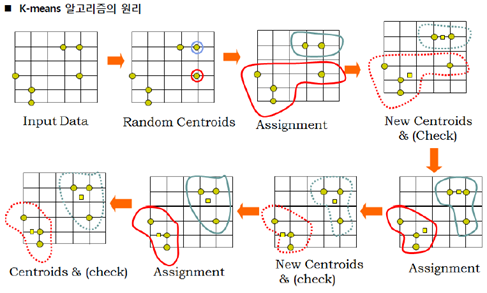 |
나. K-Means 알고리즘의 절차
|
절차 |
설명 |
|
1 |
- 군집의 수 K를 정의 |
|
2 |
- 초기 K개 군집의 중심(Centroids) 선택 |
|
3 |
- 각 관측 값들을 가장 가까운 중심의 군집에 할당 |
|
4 |
- 새로운 군집의 중심 계산 |
|
5 |
- 재정의 된 중심값 기준으로 다시 거리 기반의 군집 재분류 |
|
6 |
- 군집 경계가 변경되지 않을 때까지 반복 |
반응형
'IT기술노트 > 빅데이터' 카테고리의 다른 글
| 탐색적분석(Exploratory Data Analysis) (0) | 2021.03.03 |
|---|---|
| 데이터마이닝 알고리즘 (0) | 2021.03.03 |
| KNN(K-Nearest Neighbor) (0) | 2021.03.03 |
| 군집분석(Cluster Analysis) (0) | 2021.03.03 |
| Apriori (0) | 2021.03.03 |
| 데이터마이닝(Data Mining) (0) | 2021.03.03 |
| MOLAP, ROLAP, HOLAP (0) | 2021.03.01 |
| OLAP(Online Analysis Processing) (0) | 2021.03.01 |



댓글